AI时代,Nvidia作为HPC的头号玩家,其手中的主要利器有:高算力GPU、高速互联设备、CUDA,其中CUDA可以称之为Nvidia的护城河,只有使用CUDA才能利用Nvidia GPU进行高效的运行AI算法。
AI基础设施 | 什么是智算中心
- 三种数据中心
- 通算中心(通用服务器-以CPU为主要芯片)
- 智算中心(智算服务器-以GPU/NPU/TPU等加速芯片为主)
- 超算中心(超级计算机)
VPN | 什么是VPN
在工作、或学习中,如果连接的是内部网络,则可以直接访问内部网络资源,如果在家或出差时想要访问内部网络资源,常需要通过VPN才能访问公司/学校内部网络资源。那么VPN到底是什么呢?
TCP/IP | 秒懂TCPIP
数据包传输过程中都用到了哪些协议?
分布式训练集合通信以及集合通信原语
大模型的训练需要用到多个配有GPU的节点,GPU间通过集合通信原语进行通信,从而实现GPU间的数据交换和共享。
CPU | CPU的组成以及功能
回顾一下CPU的组成以及各组件的功能。
加速芯片 | 不同加速芯片的特点
当前,AI服务器的芯片构成为”CPU+加速芯片“,加速芯片主要有CPU、FPGA和ASIC等加速芯片,利用CPU与加速芯片的组合可以满足高吞吐量互联的需求,从而加速模型的训练(training)、推理(Inference)过程。
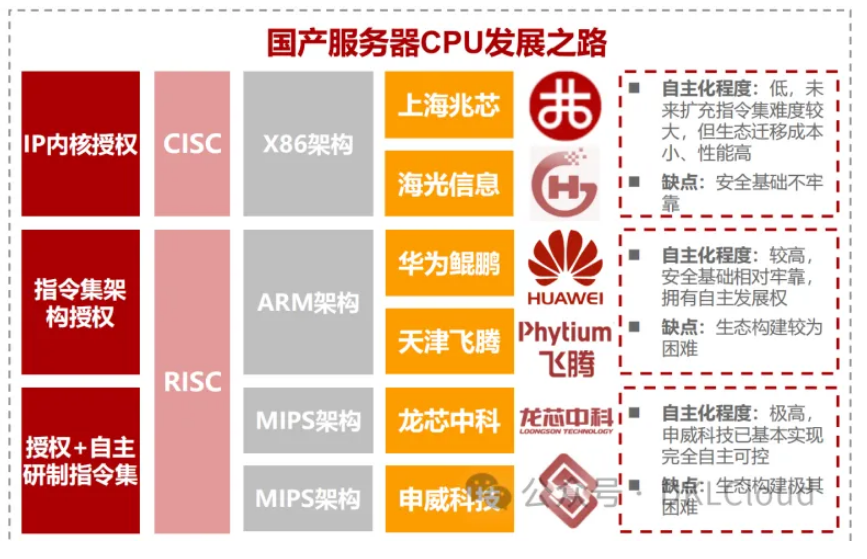
CPU | 三条国产CPU发展路线
三条国产CPU发展路线:
高速互联 | PCIe与NVLink的对比
AI算法极大程度上依赖于大数据(Big Data),AI 算法的训练对机器的算力以及数据传输能力有着非常高的要求。算力问题的解决是通过提升GPU、NPU的计算能力,并且将多块GPU/NPU连接起来组成一个算力网络(Computing Force Network, CFN)。算力网络中的不同GPU/NPU需要进行互联,GPU/NPU也需要与CPU进行互联,从而共同协作完成大量数据的运算。
AI Native | 全新软件开发模式
AI的迅猛发展,对各行各业都带来了巨大的冲击,同时也带来了新的机会,催生了AI+的产业新模式,例如AI+教育、AI+交通、AI+医疗、AI+农业等,大量的AI+应用/项目已成熟落地。AI+应用的出现、普及改变了传统的软件开发模式,实现了focus on 软件到focus on 模型的转变。