指令集定义了CPU可以执行的指令集合。指令集从复杂度分类可分为CISC和RISC指令集。CISC指令集最常见的是X86,Intel与AMD两大CPU巨头生产的CPU以X86架构为主。RISC指令集有Arm、RISC-V、MIPS、Alpha等,Arm指令集主要应用于移动端、嵌入式计算芯片。
AI模型轻量化 | 模型蒸馏
模型蒸馏的核心思想是在保持较高预测性能的同时,通过知识迁移的方式,将一个复杂的大模型(教师模型)的知识传授给一个相对简单的小模型(学生模型),极大地降低了模型的复杂性和计算资源需求,实现了模型的轻量化和高效化。
深度学习编译器 | 深度学习编译器与推理引擎的区别
AI编译器与推理引擎的区别。
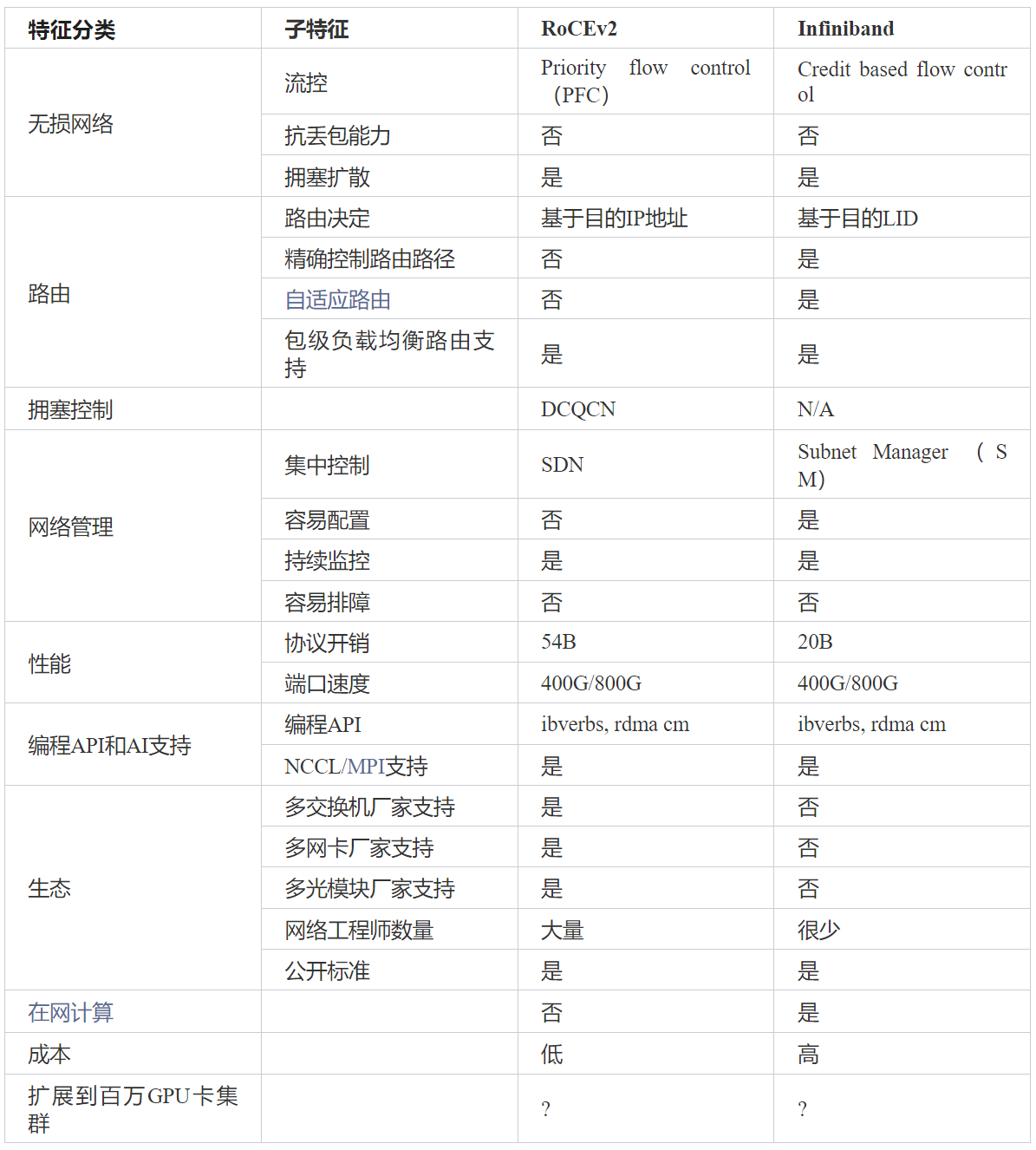
VPN | SSL VPN
SSL VPN是以SSL加密技术为基础的VPN技术,利用SSL提供的安全机制,为用户远程访问公司内部网络提供了安全保证。
SSL VPN的典型组网架构如下:
智算网络 | Scale up和Scale out网络
智算网络包含Scale-up网络和Scale-out网络两张网络。
GPU | CUDA核心与TensorCore的区别
CUDA核心和Tensor Core是NVIDIA GPU中两种不同类型的计算核心且两种核心存在明显的差别,CUDA核心数量和Tensor Core数量是反映GPU计算性能的重要参数,那么CUDA核心与Tensor Core到底是什么?
指令集 | 指令集以及国产处理器现状
- 指令集以及对应的国产处理器
- CISC
- X86
- 海光
- 兆芯
- ……
- X86
- RISC
- ARM
- 鲲鹏、飞腾、珠峰
- RISC-V
- MIPS
- 龙芯 LoongArch
- Alpha
- 申威 SW_64
- ……
- ARM
- CISC
后端优化 | 循环优化
采用深度学习编译器对深度学习代码进行编译时,在编译器后端会对IR代码进行后端优化,循环优化就包括在后端优化中,后端优化能够加速代码的运行效率。深度学习编译器编译流程如下图所示: