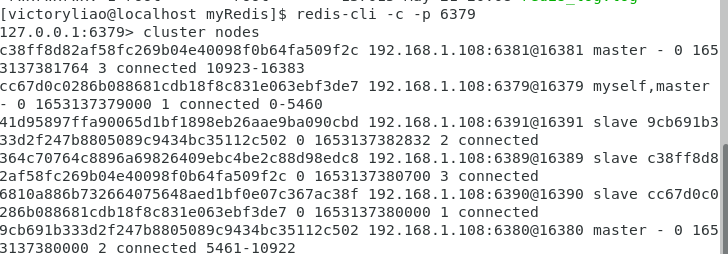
上下文切换和死锁
上下文切换
CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是,再切换前会保存上一个任务的
状态,以便切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。频繁的上下文
切换会影响多线程的执行速度。
如何减少上下文切换
(1)无锁并发编程。多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁(如采用分段锁,不同的线程处理不同段的数据)
(2)CAS算法。
(3)使用最小线程。避免创建不需要的线程(任务很少,创建了很多线程,造成大量线程阻塞等待)
死锁
死锁产生的条件
(1)互斥。一个资源同一时刻只能被一个线程拥有。
(2)请求和保持。线程在请求新的资源时,不释放已经拥有的资源。
(3)不剥夺条件。进程所获得的资源在未使用完之前,不被其他的线程强行剥夺。
(4)循环等待。竞争资源的各个线程形成一个线程等待环路。
避免死锁
破坏产生死锁的条件:
(2)在进程开始执行时就申请他所需的全部资源
(3)一个进程不能获得所需要的全部资源时便处于等待状态,等待期间他占有的资源将被隐式的释放重新加入到系统的资源列表中
,可以被其他的进程使用,而等待的进程只有重新获得自己原有的资源以及新申请的资源才可以重新启动、执行。
(4)资源有序分配(银行家算法)
死锁Demo
package concurrency;
public class DeadLockDemo {
private static String A = "A";
private static String B = "B";
public static void main(String[] args) {
new DeadLockDemo().deadLock();
}
private void deadLock(){
Thread t1 = new Thread(new Runnable(){
@Override
public void run(){
synchronized(A){
try {
Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized(B){
System.out.println("1");
}
}
}
});
Thread t2 = new Thread(new Runnable(){
@Override
public void run() {
synchronized(B){
synchronized(A){
System.out.println("2");
}
}
}
});
t1.start();
t2.start();
}
}