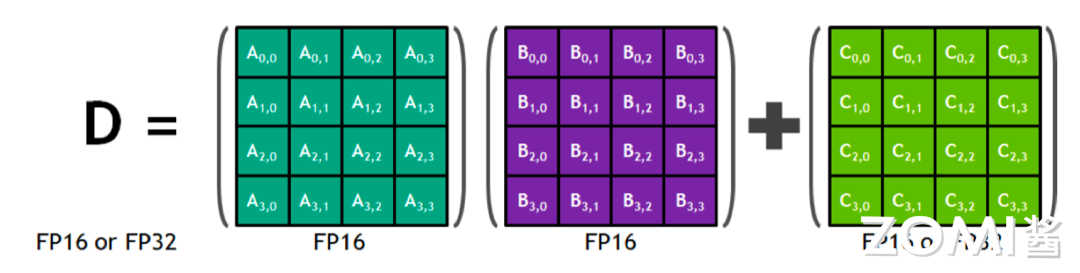
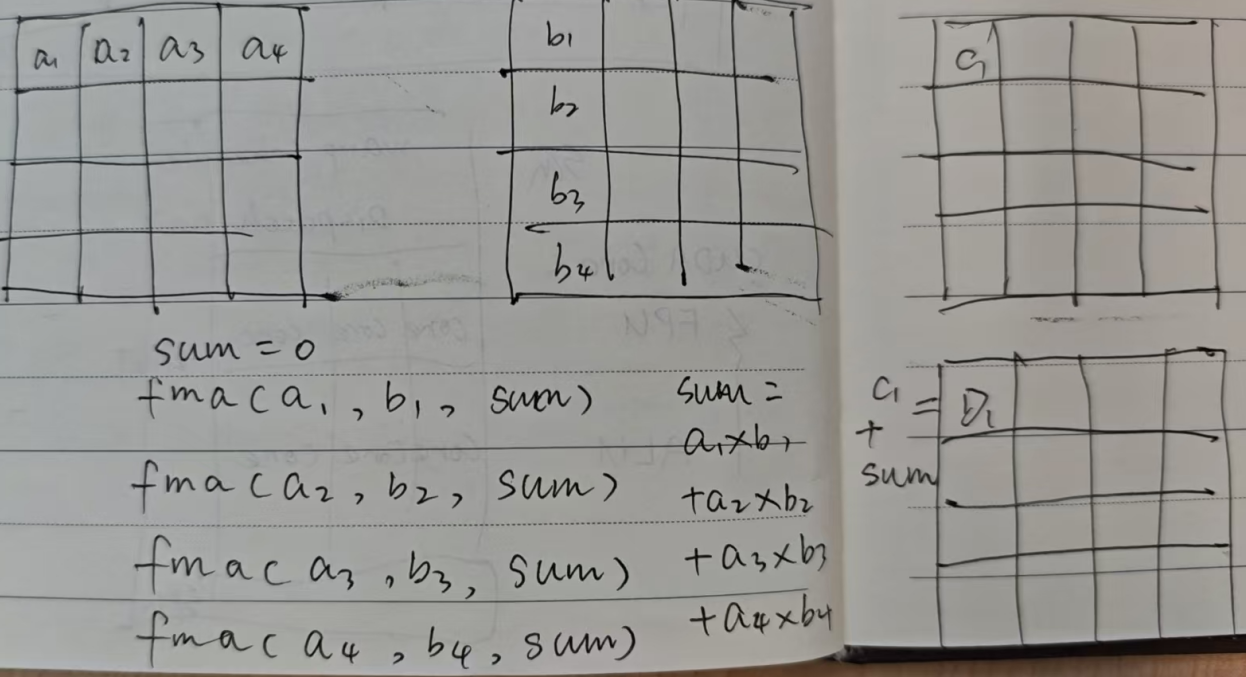
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| #include
#include
#define N 1024
__global__ void matrixFMA(float *A, float *B, float *C, float *D, int n) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < n) {
float sum = 0.0f;
for (int k = 0; k < n; ++k) {
sum = __fmaf_rn(A[row * n + k], B[k * n + col], sum);
}
D[row * n + col] = sum + C[row * n + col];
}
}
int main() {
float *A, *B, *C, *D;
float *d_A, *d_B, *d_C, *d_D;
A = new float[N * N];
B = new float[N * N];
C = new float[N * N];
D = new float[N * N];
for (int i = 0; i < N * N; i++) {
A[i] = static_cast(i);
B[i] = static_cast(2 * i);
C[i] = static_cast(3 * i);
}
cudaMalloc(&d_A, N * N * sizeof(float));
cudaMalloc(&d_B, N * N * sizeof(float));
cudaMalloc(&d_C, N * N * sizeof(float));
cudaMalloc(&d_D, N * N * sizeof(float));
cudaMemcpy(d_A, A, N * N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, N * N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_C, C, N * N * sizeof(float), cudaMemcpyHostToDevice);
int threadsPerBlock = 16;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
dim3 dimGrid(blocksPerGrid, blocksPerGrid, 1);
dim3 dimBlock(threadsPerBlock, threadsPerBlock, 1);
matrixFMA<<>>(d_A, d_B, d_C, d_D, N);
cudaMemcpy(D, d_D, N * N * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cudaFree(d_D);
delete[] A;
delete[] B;
delete[] C;
delete[] D;
return 0;
}
|