三种 RDMA技术RoCE、iWARP,后两者是基于以太网的技术,IB的链路层进行了重新设计。
随着大模型以及AIGC的快速发展,AI对于算力有了更高的要求。从最开始使用单机单卡(CPU+GPU)进行DL模型训练推理,到使用单机多卡(CPU+GPUs),再到多机多卡的AI集群。
集中更多的算力可以加速AI模型的训练,但只有强大的AI算力是不够的,AI模型的训练是从大量数据中学习规律、学习知识,AI的训练过程设计大量的数据搬运,需要高带宽、低延时的数据传输。高速互联技术能够将不同的算力芯片或服务器连接在一起组成一个算力网络,并提供高速的数据传输能力。
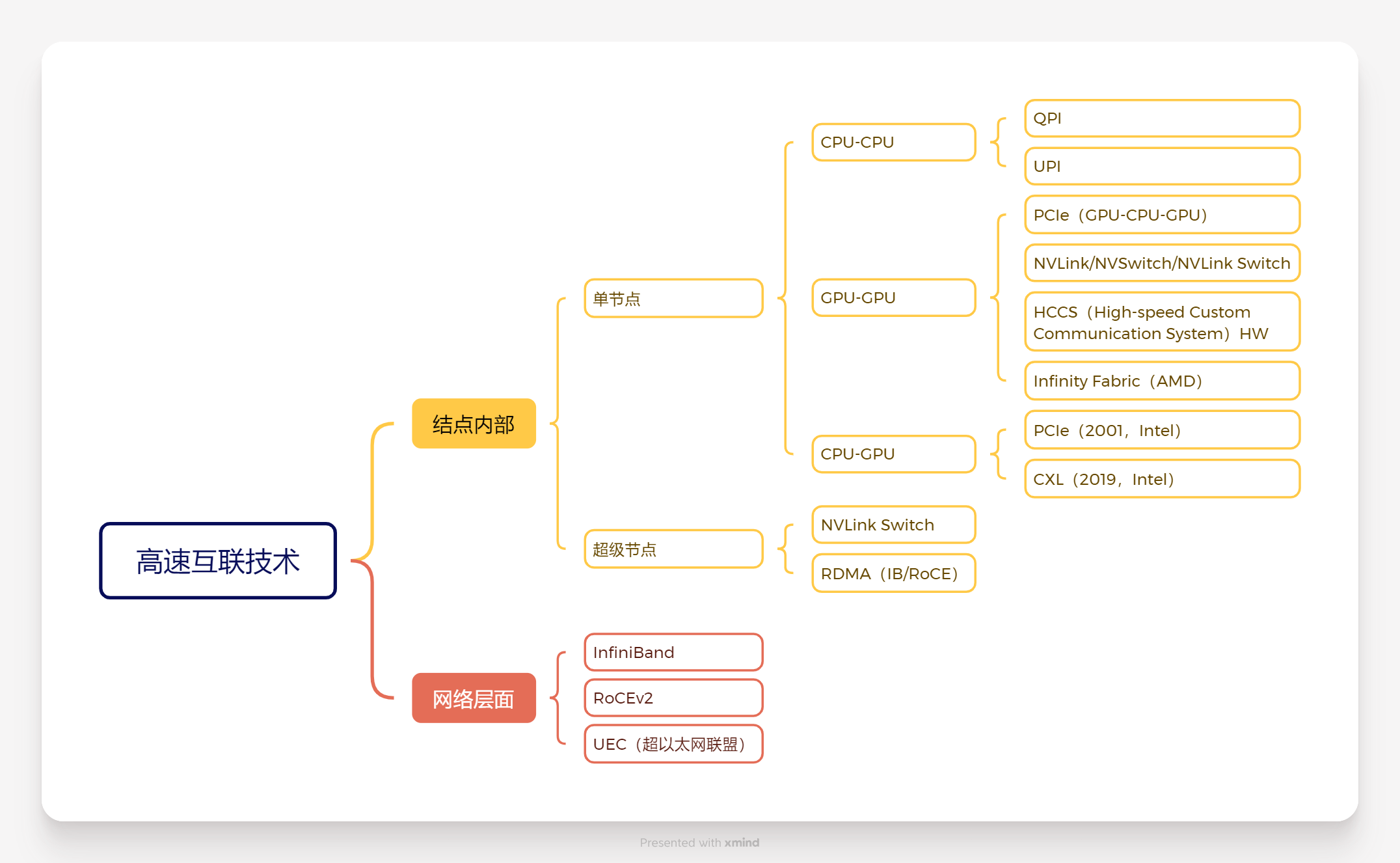
高速互联分为结点内部计算设备的互联与结点间的互联。结点内互联又分为单节点互联与超级结点互联。单节点互联能够实现两个计算设备的互联,例如CPU与CPU之间通过UPI(Ultra Path Interconnect)进行连接,GPU与GPU可以通过PCIe(Intel于2001年开发)/NVLink(Nvidia开发)/Infinity Fabric(AMD开发)进行互联,CPU与GPU之间通过PCIe或者CXL(Compute Express Link,Intel于2019年提出的高速互联协议)进行互联。超级结点互联能够实现多个计算设备的互联,例如多GPU间的互联可以使用NVLink Switch或RDMA进行互联。
机间互联通过RDMA(Remote Direct Memory Access)进行互联,RDMA常见的有三种实现:InfiniBand、RoCE、iWarp,使用最为广泛的是IB和RoCE(RoCEv2),RoCE、iWARP,后两者是基于以太网的技术,IB的链路层进行了重新设计。