AI算法极大程度上依赖于大数据(Big Data),AI 算法的训练对机器的算力以及数据传输能力有着非常高的要求。算力问题的解决是通过提升GPU、NPU的计算能力,并且将多块GPU/NPU连接起来组成一个算力网络(Computing Force Network, CFN)。算力网络中的不同GPU/NPU需要进行互联,GPU/NPU也需要与CPU进行互联,从而共同协作完成大量数据的运算。
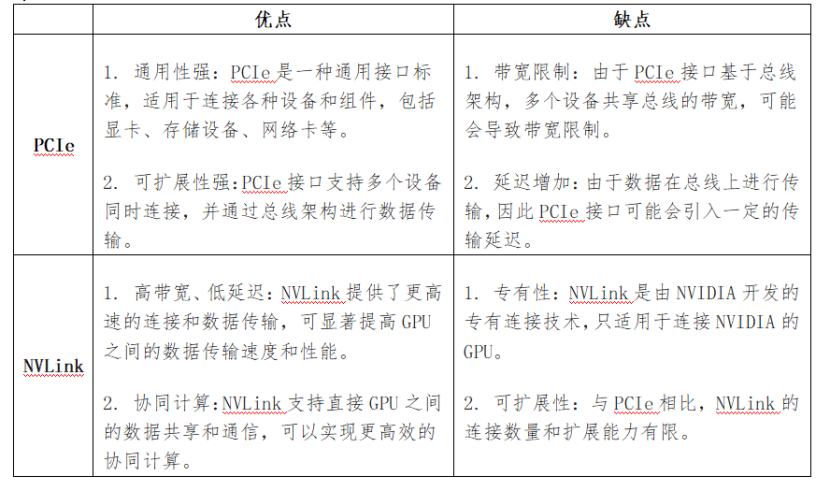
目前的GPU互联方式主要有两种:PCIe和NVLink,在同一个机器内,PCIe负责CPU与GPU之间的通信,NVlink负责GPU与GPU之间的通信。机器间的通信可通过TCP/IP网络协议或RDMA网络协议(InfiniBand、iWARP、RoCE)进行。
PCIe(PCI-Express)
Peripheral Component Interconnect Express的简称,它是一种
内部总线,也是一种计算机扩展总线标准,是一种高速串行、高带宽扩展总线,通常用于主板上连接显卡、固态硬盘以及采集卡和无线网卡等外设。PCIe的两种存在形式:
M.2接口和PCIe标准插槽。加速卡、高带宽网卡和显卡一般都是安装在插槽中。固态硬盘、笔记本网卡等一般使用M.2接口。PCIe数据传输速率
协议(Protocol) 传输速率/Gbps PCIe1.0 2.5 PCIe2.0 5.0 PCIe3.0 8.0 PCIe4.0 16 PCIe5.0 32 PCIe6.0 64
NVLink
NVLink是一种高速互连技术,旨在加快CPU 与 GPU、GPU 与 GPU之间的数据传输速度,提高系统性能。NVLink高速互联的两种形式:直连、NVSwitch。
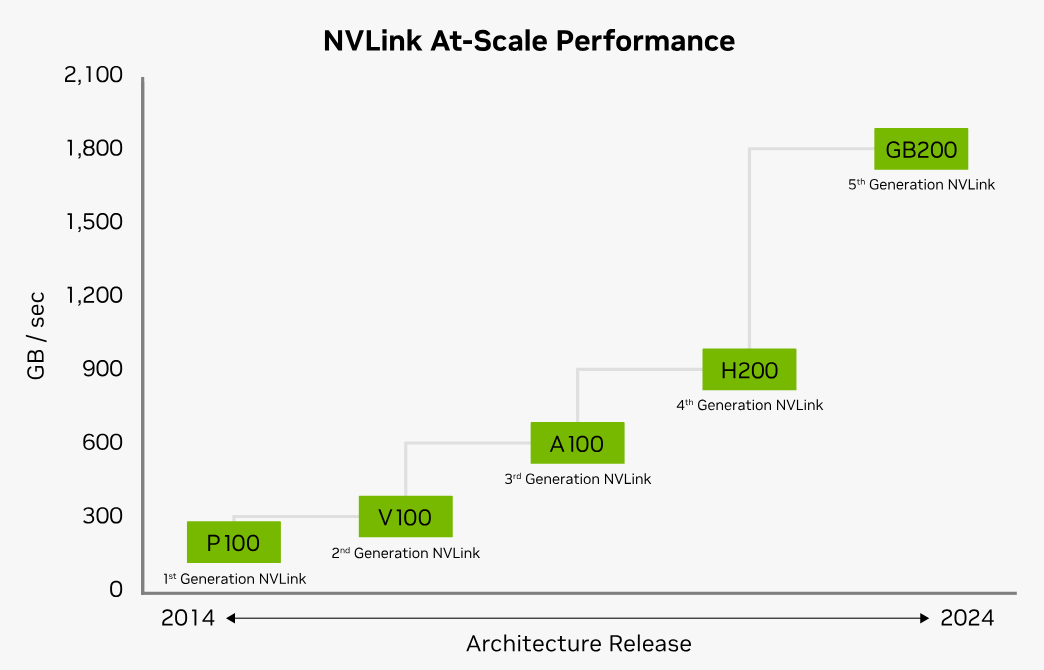
NVLink数据传输速率
协议(Protocol) 发布时间 显卡 最大链数 GPU之间总带宽 应用架构 NVLink 1.0 2016 P100 4 160GB/s Pascal NVLink 2.0 2017 V100 6 300GB/s Volta NVLink 3.0 2020 A100 12 600GB/s Ampere NVLink 4.0 2022 H100 18 900GB/s Hopper NVLink 5.0 2024 GB200 18 1800GB/s Blackwell
PCIe VS NVLink