RDMA(Remote Direct Memory Access)技术起初是为了缓解CPU的压力,提高CPU利用率,从而提高系统性能。随着人工智能(AI)、AIGC以及大模型(LLM)的快速发展,AI对于计算设备的算力以及数据处理能力有了更高的要求。
AI模型训练过程中需要反复、多次的在host侧(CPU)和device侧(GPU)之间进行大量数据的搬运,因此提升设备的数据搬运能够加快模型的训练。
传统的数据交换是通过socket进行通信,socket通信过程中,需要为TCP连接建立socket句柄,每次传输通信都要经过OS,因此数据传输效率不高。RDMA在每个服务器的网卡(Network Interface Card, NIC)中实现。通过绕过操作系统和网络内核,两台服务器之间的网络性能和数据交换会更快。传统socket通信类似于以红包的形式发压岁钱,需要长辈将钱先放入红包,然后晚辈收到红包之后,再拆开红包,才能获得红包中的钱。RDMA通信类似于如今比较流行的支付宝/微信转账方式,钱直接从一方到另一方,不需要“中转站”。
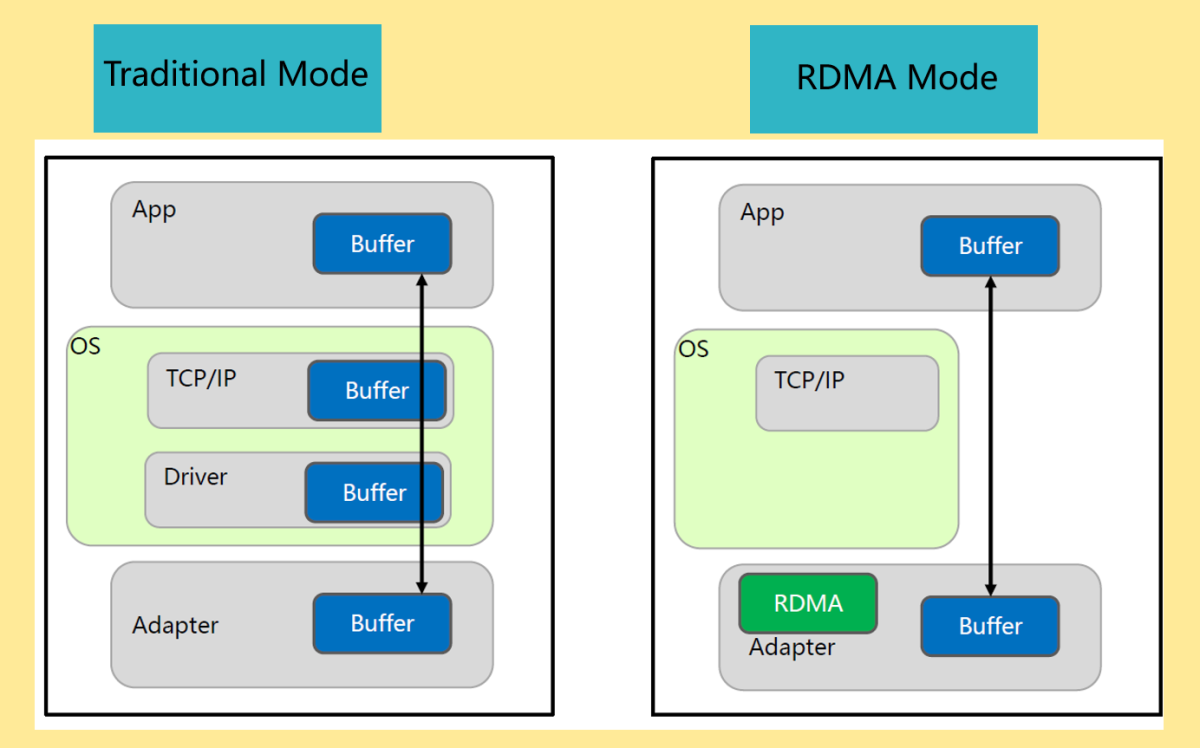
RDMA具有高带宽、低延迟、低CPU消耗三种特点。
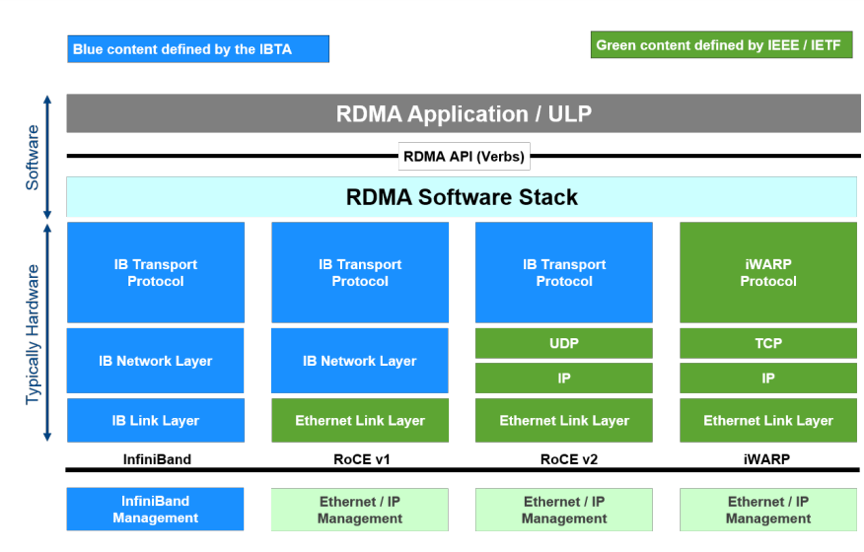
支持RDMA的三种网络协议:
- InfiniBand(IB)
- RoCE(RDMA over converged Ethernet)
- RoCE v1
- RoCE v2
- iWARP(RDMA over TCP/IP)
参考链接1:AI 网络,为什么需要RDMA?
参考链接2:RoCE vs iWARP 十问十答