FlagGems介绍
FlagGems是基于OpenAITriton编程语言实现的高性能通用算子库,能够为大语言模型提供一系列可应用于PyTorch框架的算子,加速模型的推理与训练。FlagGems通过对
PyTorch的后端aten算子进行覆盖重写,实现算子库的无缝替换,使用户能够在不修改模型代码的情况下平稳地切换到triton算子库。FlagGems不会影响aten后端的正常使用。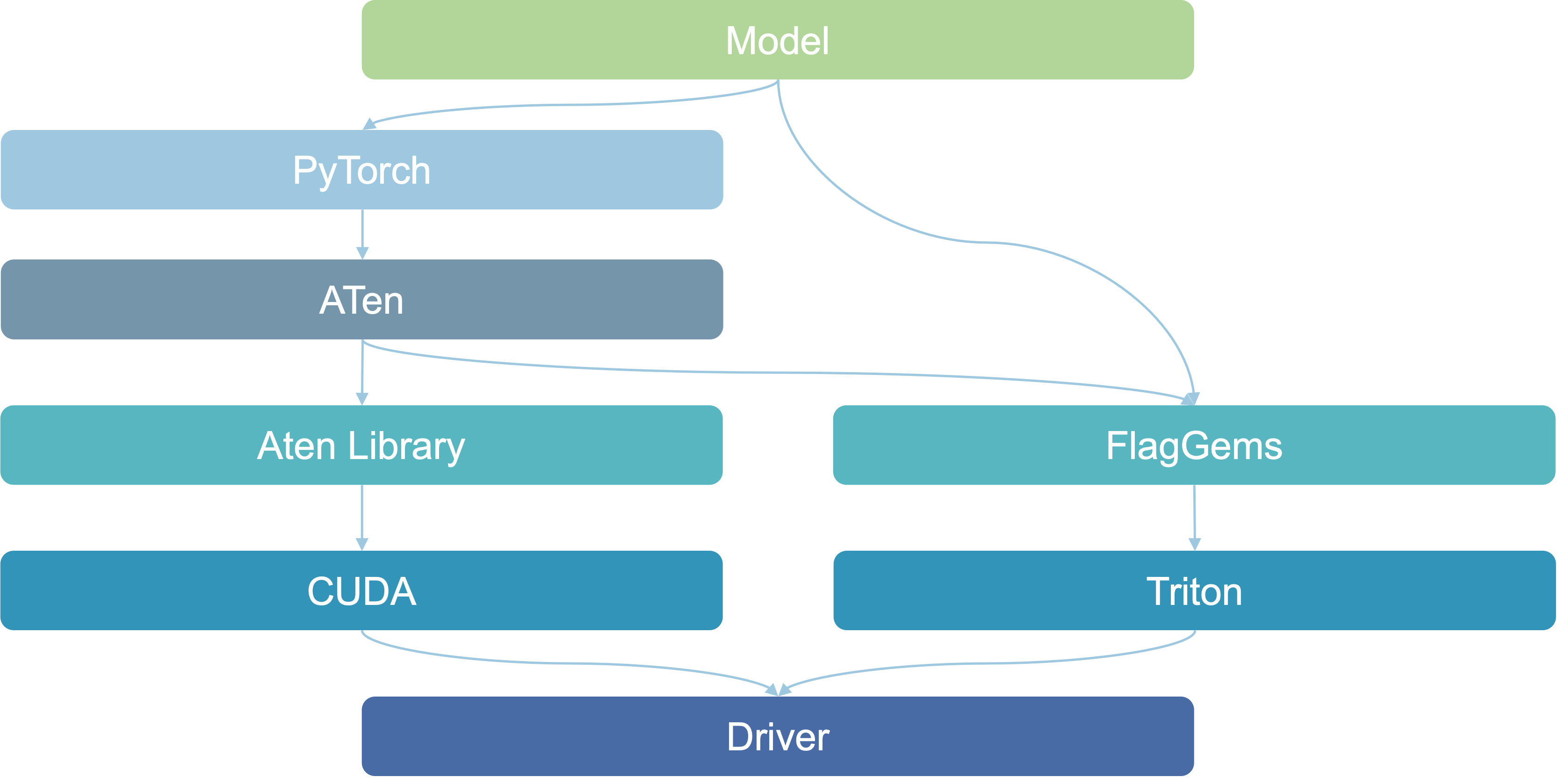
在pytorch中,核心的张量操作以及底层硬件通信是由ATen库实现的,当ATen需要执行一些可以在GPU上加速的操作时,它会通过CUDA来调用GPU的资源。具体来说,pytorch提供了易于使用的高层API,而ATen则提供张量计算和底层硬件通信。
FlagGems的技术路线
FlagGems的技术路线选择的是统一开源算子库
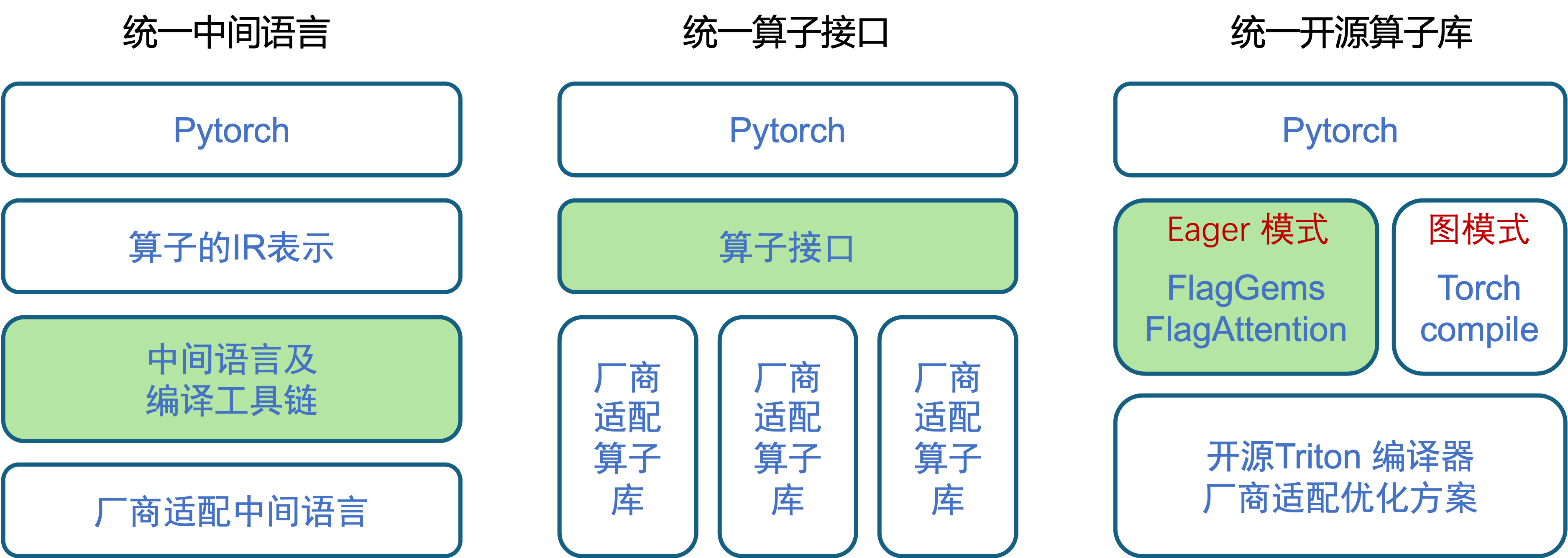
FlagGems Github仓库
基础环境
- 系统类型:
linux - CUDA version: 12.1
- 系统类型:
FlagGems环境准备、搭建,环境搭建脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20create virtual env.
conda create -n flag-gems-test python==3.10
activate created virtual env.
conda activate flag-gems-test
install pytorch in virtual env.
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
install pytest in virtual env for running test code.
pip install pytest
clone "FlagGems" from github repository.
git clone https://github.com/FlagOpen/FlagGems.git
change directory to "FlagGems/“.
cd FlagGems
install "FlagGems".
pip install .测试
创建demo.py python文件并输入以下内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# 导入pytorch
import torch
# 导入FlagGems
import flag_gems
M, N, K = 1024, 1024, 1024
# 创建M行K列的矩阵A
A = torch.randn((M, K), dtype=torch.float16, device="cuda")
# 输出矩阵A
print(A)
# 创建K行N列的矩阵B
B = torch.randn((K, N), dtype=torch.float16, device="cuda")
# 输出矩阵B
print(B)
# 启用FlagGems
with flag_gems.use_gems():
# 矩阵乘法
C = torch.mm(A, B)
# 输出矩阵乘法结果
print(C)运行demo
1
python demo.py
运行结果
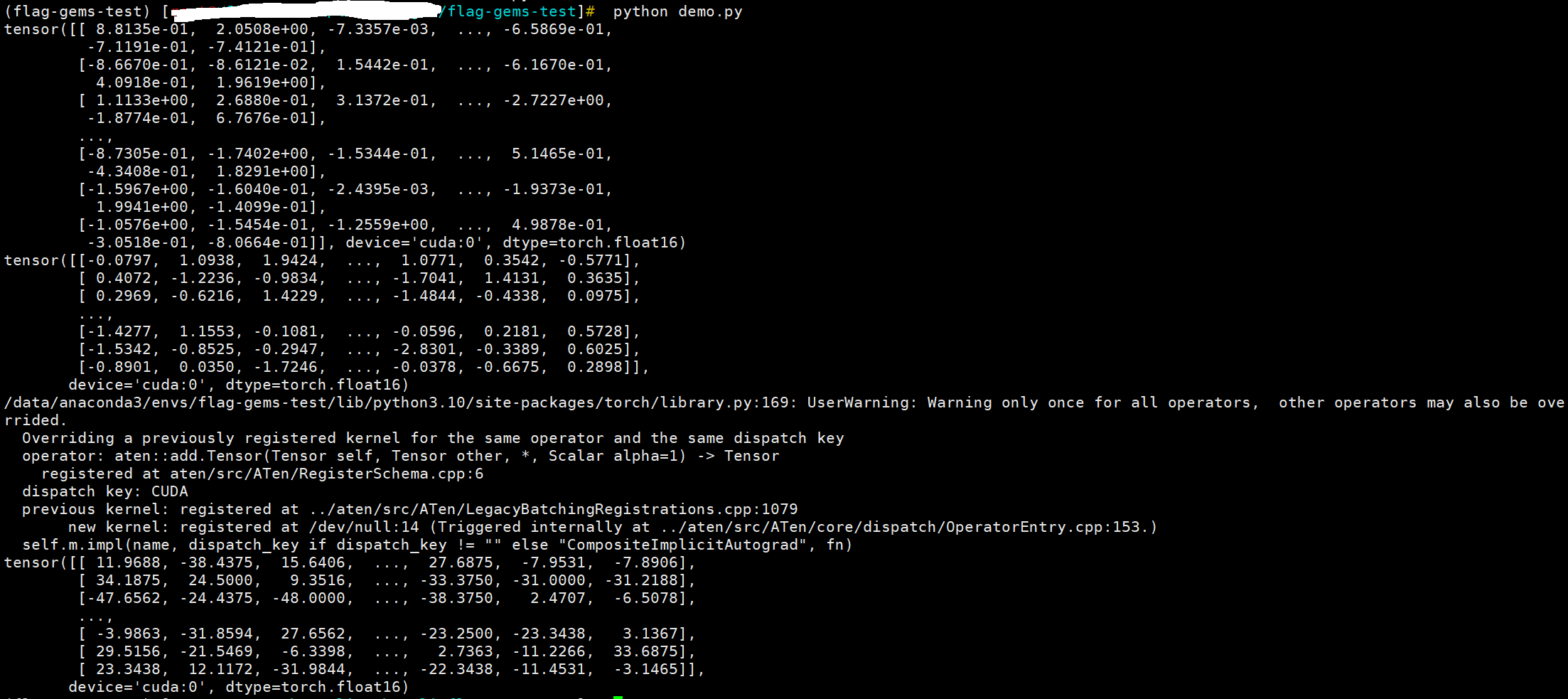
算子以及模型正确性测试等参考github仓库介绍