Logistic回归
Logistic回归是一种分类算法,通常用于二分类问题(例如:明天是否会下雨),但也可以用于多分类问题。
Logistic回归与梯度上升算法
Logistic回归
回归:利用一条直线对一些数据点进行拟合的过程。
Logistic回归是分类方法,它利用的是Sigmoid函数阈值在[0,1]这个特性。
Logistic回归进行分类的主要思想:根据现有数据对分类边界线建立回归公式,以此进行分类
其实,Logistic回归本质上是一个基于条件概率的判别模型(Discriminative Model)。
Sigmoid函数(Logistic函数):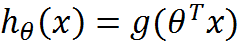
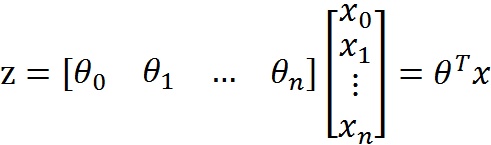
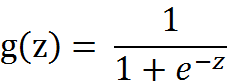
整合成一个公式: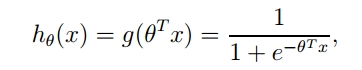
Sigmoid函数的图像: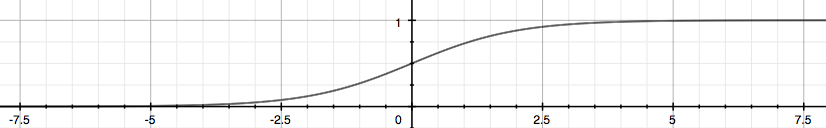
z是一个矩阵,θ是参数列向量(要求解的),x是样本列向量(给定的数据集)。θ^T表示θ的转置。g(z)函数实现了任意实数到[0,1]的映射,这样我们的数据集([x0,x1,…,xn]),不管是大于1或者小于0,都可以映射到[0,1]区间进行分类。hθ(x)给出了输出为1的概率。比如当hθ(x)=0.7,那么说明有70%的概率输出为1。输出为0的概率是输出为1的补集,也就是30%。
如果我们有合适的参数列向量θ([θ0,θ1,…θn]^T),以及样本列向量x([x0,x1,…,xn]),那么我们对样本x分类就可以通过上述公式计算出一个概率,如果这个概率大于0.5,我们就可以说样本是正样本,否则样本是负样本。
如何得到合适的参数向量θ?
根据sigmoid函数的特性,我们可以做出如下的假设:
两个概率公式合而为一:(损失函数-Loss Function)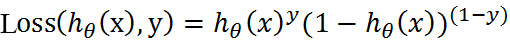
取对数: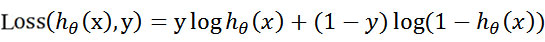
这个损失函数,是对于一个样本而言的。给定一个样本,我们就可以通过这个损失函数求出,样本所属类别的概率,而这个概率越大越好,所以也就是求解这个损失函数的最大值。既然概率出来了,那么最大似然估计也该出场了。假定样本与样本之间相互独立,那么整个样本集生成的概率即为所有样本生成概率的乘积,再将公式对数化,便可得到如下公式: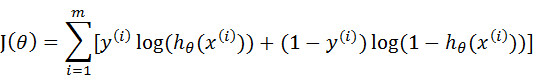
其中,m为样本的总数,y(i)表示第i个样本的类别,x(i)表示第i个样本,需要注意的是θ是多维向量,x(i)也是多维向量。
综上所述,满足J(θ)的最大的θ值即是我们需要求解的模型。
怎么求解使J(θ)最大的θ值呢?因为是求最大值,所以我们需要使用梯度上升算法。如果面对的问题是求解使J(θ)最小的θ值,那么我们就需要使用梯度下降算法。面对我们这个问题,如果使J(θ) := -J(θ),那么问题就从求极大值转换成求极小值了,使用的算法就从梯度上升算法变成了梯度下降算法,它们的思想都是相同的,学会其一,就也会了另一个。
梯度上升算法
爬坡这个动作用数学公式表达即为: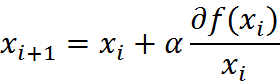
其中,α为步长,也就是学习速率,控制更新的幅度。
梯度上升迭代公式: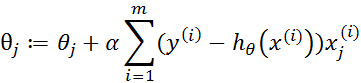
总结
Logistic回归的一般过程:
1.收集数据:采用任意方法收集数据。
2.准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
3.分析数据:采用任意方法对数据进行分析。
4.训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
5.测试算法:一旦训练步骤完成,分类将会很快。
6.使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数,就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
Logistic回归的优缺点
优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低。
缺点:容易欠拟合,分类精度可能不高。
其他
1.Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法完成。
2.改进的一些最优化算法,比如sag。它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批量处理。
机器学习的一个重要问题就是如何处理缺失数据。这个问题没有标准答案,取决于实际应用中的需求。现有一些解决方案,每种方案都各有优缺点。
3.我们需要根据数据的情况,这是Sklearn的参数,以期达到更好的分类效果。