决策树
决策树(Decision Tree)是一种基本的分类与回归方法。决策树由结点(Node)和有向边(Directed Edge)组成。结点有两种类型:内部结点(Internnal Node)和叶结点(Leaf Node)。内部结点表示一个特征或属性,叶结点表示一个类。决策树还有一个唯一的根结点(Root Node)。
我们可以把决策树看成一个if-then规则的集合,将决策树转换成if-then规则的过程是这样的:
由决策树的根结点到叶结点的每一条路径构建一条规则;路径上内部结点的特征对应着规则的条件,而叶结点对应着规则的结论。
决策树的路径或其对应的if-then规则集合具有一个重要性质:互斥并且完备(每一个实例都只能被一条路径或一条规则所覆盖(覆盖:实例的特征与路径上的特征一致或实例满足规则的条件))。
决策树做预测的步骤
1.收集数据
2.准备数据(将收集的数据按照一定规则整理出来,方便后续进行处理)
3.分析数据(在决策树构造完成后,检查决策树图形是否符合预期)
4.训练算法(构造决策树/决策树学习—>构造一个决策树的数据结构)
5.测试算法(使用经验树计算错误率。当错误率达到可接受范围,这个决策树就可以投放使用)
6.使用算法(决策树可以更好地理解数据的内在含义)
如何构建决策树?—构建决策树的3个步骤
1.特征选择
特征选择就是决定用哪个特征来划分特征空间
特征选择在于选取训练数据具有分类能力的特征
特征选择的标准:信息增益(Information Gain)/信息增益比。信息增益:在划分数据集之后信息发生的变化。
Note:信息增益最高的特征是最好的选择
1.1香农熵(熵)-信息论之父克劳德.香农:集合信息的度量方式。
熵定义为信息的期望值。在信息论与概率论中,熵是表示随机变脸不确定性的度量。如果待分类的事物可能划分在多个分类之中,则符号xi的信息定义为: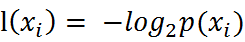
其中p(xi)是该分类的概率。
通过上式,我们可以得到所有类别的信息。为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值(数学期望-反应随机变量平均取值的大小),公式如下: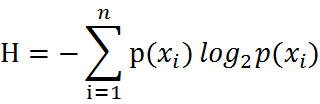
其中n是分类的数目。熵越大,随机变量的不确定性就越大。
当熵中的概率由数据估计(特别是最大似然估计-Maximum Likelihood Estimation)得到时,所对应的熵称为经验熵(Empirical Entropy)
我们定义样本数据表中的数据为训练数据集D,则训练数据集D的经验熵为H(D),|D|表示其样本容量,及样本个数。设有K个类Ck, = 1,2,3,…,K,|Ck|为属于类Ck的样本个数,因此经验熵公式就可以写为 :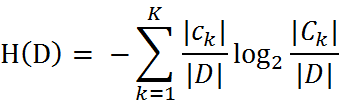
1.2信息增益
如何选择特征,需要看信息增益。也就是说,信息增益是相对特征而言的,信息增益越大,特征对最终的分类结果影响也就越大,我们就应该选择对最终分类结果影响最大的那个特征作为我们的分类特征。
条件熵H(Y|X)表示在一直随机变量X的条件下随机变量Y的不确定性,随机变量X给定条件下随机变量Y的条件熵(Conditional Entropy)H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望: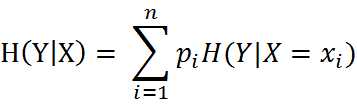
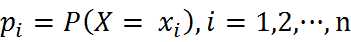
当条件熵中的概率由数据估计(特别是极大似然估计)得到时,岁对应的条件熵称为条件经验熵(empirical conditional entropy)。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即: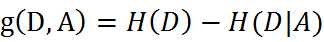
Note:一般地,熵H(D)与条件熵H(D|A)之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
设特征A有n个不同的取值{a1,a2,···,an},根据特征A的取值将D划分为n个子集{D1,D2,···,Dn},|Di|为Di的样本个数。记子集Di中属于Ck的样本的集合为Dik,即Dik = Di ∩ Ck,|Dik|为Dik的样本个数。于是经验条件熵的公式可以些为: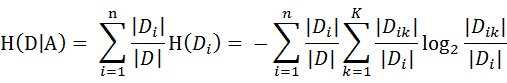
总结
决策树的一些优点
1.易于理解和解释。决策树可以可视化。2.几乎不需要数据预处理。其他方法经常需要数据标准化,创建虚拟变量和删除缺失值。决策树还不支持缺失值。
3.使用树的花费(例如预测数据)是训练数据点(data points)数量的对数。
4.可以同时处理数值变量和分类变量。其他方法大都适用于分析一种变量的集合。
5.可以处理多值输出变量问题
6.使用白盒模型.如果一个情况被观察到,使用逻辑判断容易表示这种规则。相反,如果是黑盒模型(例如人工神经网络),结果会非常难解释。
7.即使对真实模型来说,假设无效的情况下,也可以较好的使用
决策树的一些缺点
1.决策树学习可能创建一个过于复杂的树,并不能很好的预测数据。也就是过拟合。修剪机制(现在不支持),设置一个叶子节点需要的最小样本数量,或者数的最大深度,可以避免过拟合。2.决策树可能是不稳定的,因为即使非常小的变异,可能会产生一颗完全不同的树。这个问题通过decision trees with an ensemble来缓解。
3.概念难以学习,因为决策树没有很好的解释他们,例如,XOR, parity or multiplexer problems(奇偶校验或多路复用器问题)。
4.如果某些分类占优势,决策树将会创建一棵有偏差的树。因此,建议在训练之前,先抽样使样本均衡。